OVERVIEW
Hybrid cloud data management for Pfizer, Nike, and 50+ enterprise clients
Komprise provides hybrid cloud data management for enterprises managing petabytes of unstructured data across on-premises and cloud storage. Clients like Pfizer need to locate HIPAA-regulated patient data across multiple storage tiers; Nike needs to find seasonal campaign assets across global teams. The VP of Product had already decided to add a tagging system to Komprise's data management platform. My role was not whether to build tagging, but how to design a classification system that would actually change the way users organize and retrieve data. The existing system relied entirely on attribute-based filters (file size, date modified, file type), forcing users to construct complex queries to find data they thought about in business terms.
QUERY TIME
-62%
Average time to group target data dropped from 8 minutes to 3 minutes
SUPPORT TICKETS
-63%
Monthly filtering-related tickets declined from 8 to 3, freeing CS team capacity
POLICY AUTOMATION
+200% adoption rate
IT Admins applied tags to automated migration and backup policies faster than projected, validating the dual-use IA design
PROBLEM
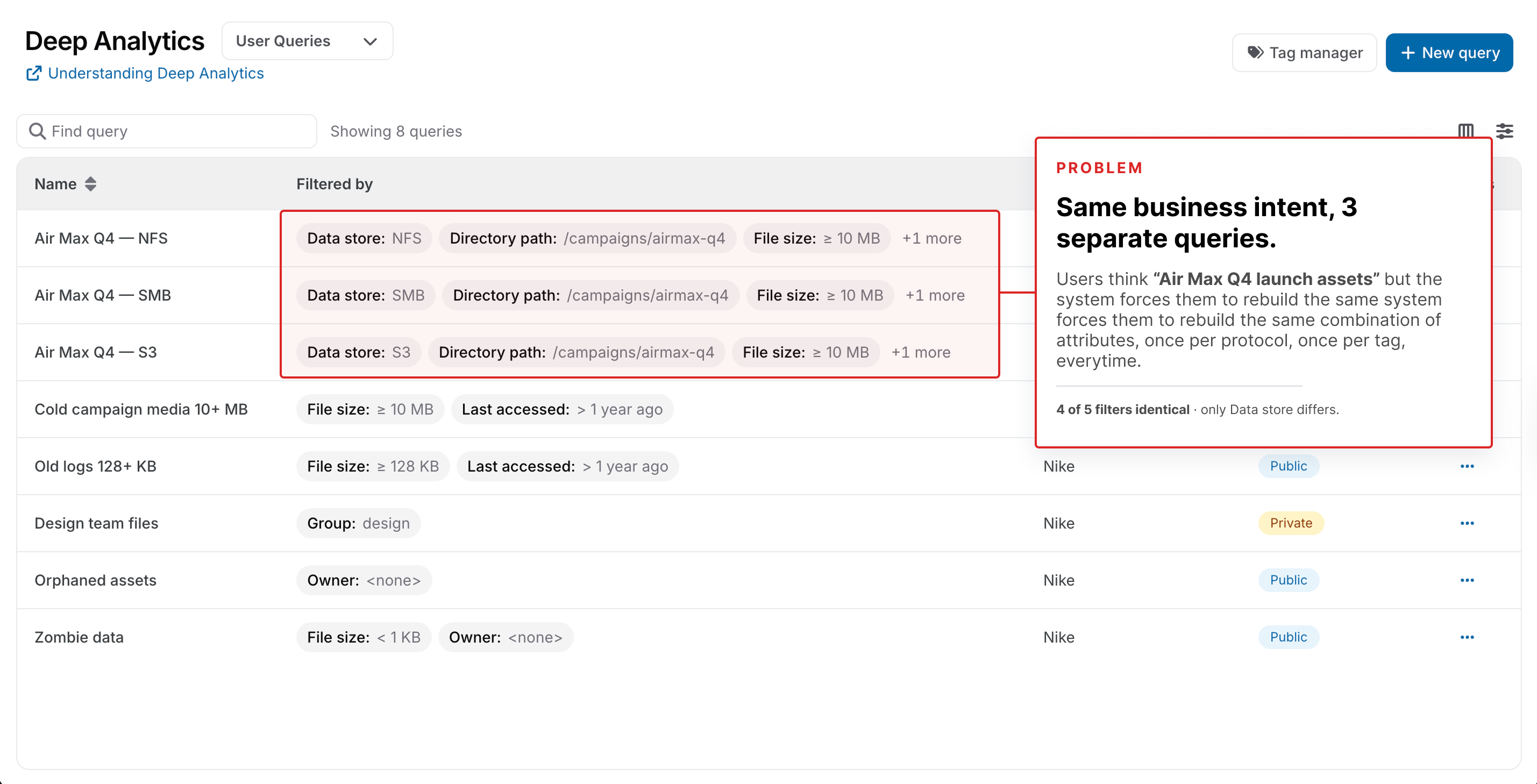
Users couldn't find their data because the system filtered by attributes, not by meaning
Users spent an average of 8 minutes constructing a single data query, and 24% of all support tickets were filtering-related (18 tickets in March 2024 alone). But the core problem was not speed. Users repeated the same filter combinations 4.2 times on average, indicating they were trying to express a concept the system could not represent. A compliance officer searching for "all HIPAA-regulated patient data" had to manually combine file type, location, and date filters, then repeat this combination every time. The system's structure filtered by technical attributes when users thought in business concepts. This was a structural mismatch, not a performance problem.
Average query creation time was 8 minutes, with users manually combining 3-5 file attributes per search
RESEARCH & DISCOVERY
Filter speed was not the problem. The system had no memory for meaning
I conducted research with 6 users stratified across two personas (3 Restricted Users and 3 IT Admins), spanning healthcare, media, and retail verticals. The core reframing emerged here: the problem was not filter performance but the system's inability to remember meaning. Users thought in business concepts ("compliance documents," "campaign assets") but the system only spoke in technical attributes. Even 10x faster filters would not solve this, because users would still reconstruct the same conceptual queries every session.

4.2x query repetition
The same filter combinations appeared 4.2 times on average across sessions, meaning users were trying to express a concept the system could not store. This was the clearest signal that tagging needed to function as persistent meaning, not faster filtering.
Two personas, two purposes for tags
Restricted Users saw tags as search shortcuts to avoid rebuilding queries. IT Admins saw tags as policy triggers for automated migration and backup. The IA had to support both mental models without overwhelming either.
Competitive gap in bulk creation
AWS, Azure, and Google Cloud all required row-by-row key-value input, roughly 40 individual fields to create 20 tags. This bottleneck directly informed the comma-separated bulk input pattern.
DESIGN PROCESS
From user mental models to validated IA structure
The process began with understanding user mental models through interviews, then moved into IA prototyping where I tested two structural approaches with production-scale data. I brought the backend lead into the structural decision early by sharing test results rather than arguing for a preference. This earlier collaboration prevented the two-week rework that could have occurred if I had decided in isolation and handed over the IA after design was locked.
Discovery and Research
Conducted 6 targeted user interviews with Restricted Users and IT Admins, plus competitive benchmarking across AWS, Azure, and Google Cloud to validate the key-value tagging direction.
IA Exploration
Prototyped two structural approaches for the Tag Library, accordion and drill-down, and tested with realistic data volumes (50+ tag values per category) to validate scanning and orientation.
Persona-Specific Workflows
Designed separate interaction models for Restricted Users (browse-and-apply) and IT Admins (create-manage-apply-delete), ensuring each workflow matched their mental model and use frequency.
Engineer Collaboration
Included backend lead in IA prototyping sessions to validate technical feasibility and prevent late-stage API restructuring, adding two weeks of timeline upfront to save longer rework later.
Validation Testing
Ran iterative testing with bulk-tag creation, confirmation modals, and drill-down navigation to confirm the IA prevented errors and disorientation at scale.
DESIGN GOAL
Three explicit goals that translated research findings into the system's shape
Before drawing any UI, I translated the research findings into explicit design goals. Three insights from the dual-persona research each demanded a distinct goal that the IA had to satisfy without compromising the others. Starting from these goals — rather than from a feature wishlist — kept the solution honest to the research and gave each Solution component a clear reason to exist.
Persistent meaning: Tags must function as memory, not as another filter. Whatever shape the system took, it had to survive across sessions and replace the 4.2x rebuild loop. This was the foundational goal — without it, every other improvement would just speed up a broken pattern.
Two access paths, one data model: Restricted Users and IT Admins needed opposite workflows but couldn't drift into separate systems that would fragment the underlying tag data. The data layer had to stay unified while the UX layer split into persona-specific entry points.
Bulk efficiency, individually correctable: Competitive benchmarking exposed a gap. Existing solutions forced a tradeoff between bulk creation speed and per-item error handling. The goal was to deliver both: bulk submission with per-item review and correction, no all-or-nothing failures.
SOLUTION
A three-part tagging system: Tag Library, Apply Tags, and Un-tag
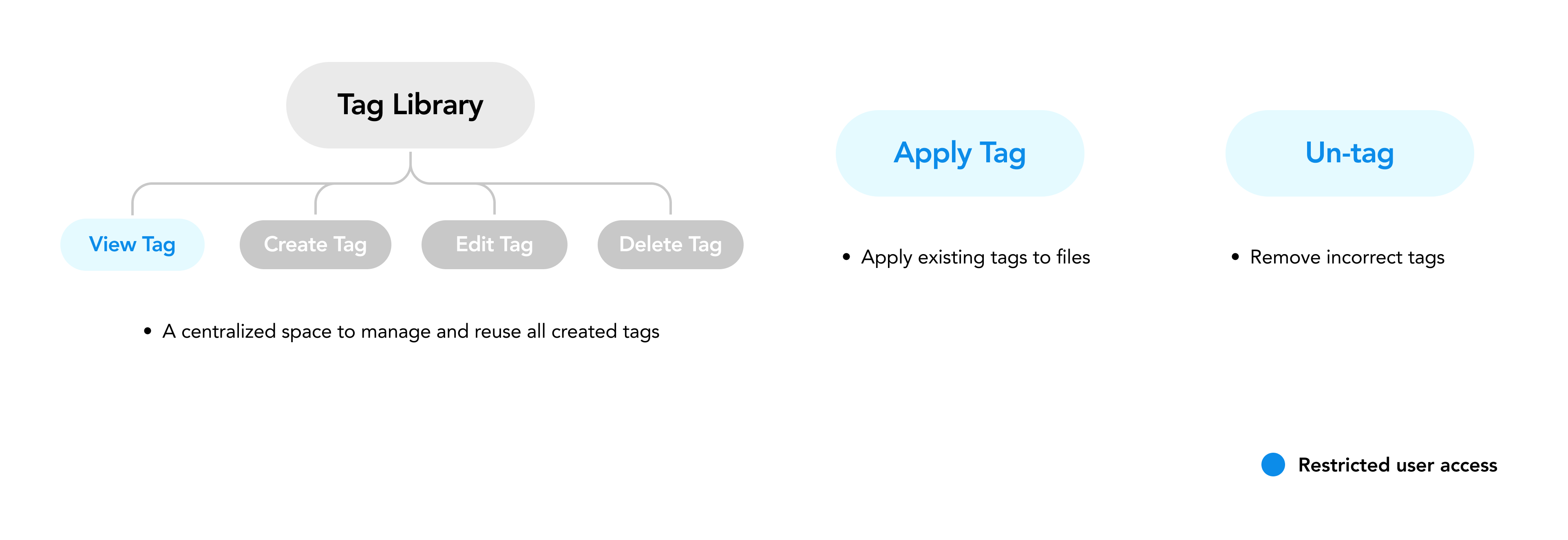
Research confirmed two things: Restricted Users only needed "find and apply," while IT Admins needed full lifecycle control. A single unified UI for both would produce a compromise that served neither. So I designed one shared tag data model expressed through three independent entry points, each optimized for a distinct workflow. Tag Library used the drill-down structure for browsing and managing all tags, optimized for the IT Admin persona's need to oversee the full taxonomy. Apply Tags provided a streamlined flow for both personas, featuring comma-separated bulk input, a pattern identified from the competitive benchmarking gap where existing solutions required 40 individual inputs for 20 tags. Un-tag included confirmation modals for batch operations, designed to build trust rather than create friction. When users manage 80,000+ files, they need confidence in the scope of their actions before committing.
Drill-down Tag Library with role-based access control. IT Admins create and manage tags in a centralized hub, Restricted Users browse and apply existing tags from the Data Browser
Comma-separated bulk-tag creation for admins replacing row-by-row key-value forms, reducing the effort to create 20-30 tags from 40+ inputs to a single action with visual preview
Confirmation modals for Apply and Un-tag showing estimated file counts, giving admins confidence about the scale of their batch actions before committing
KEY DECISION 1
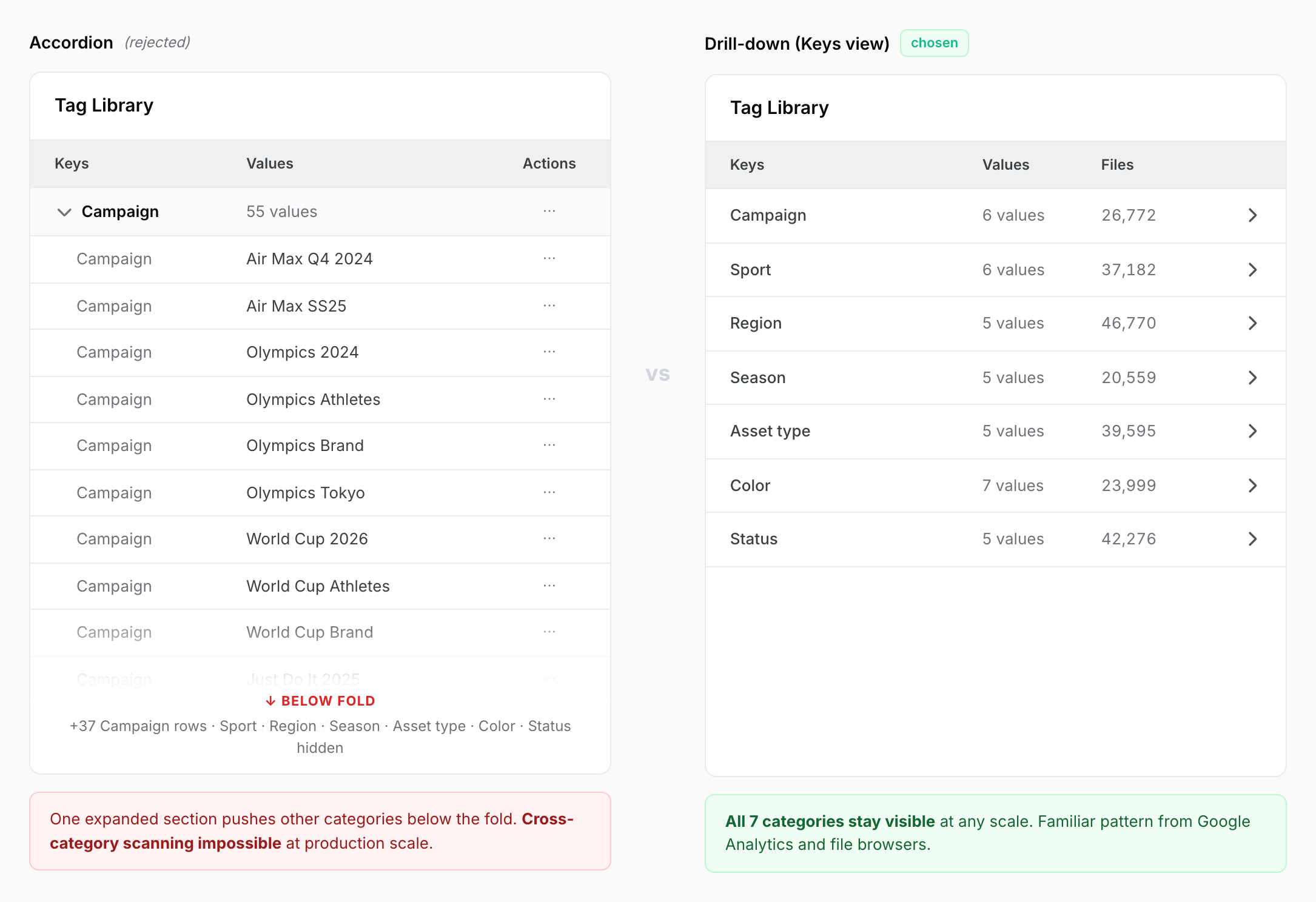
Choosing drill-down over accordion, accepting deeper clicks for better scalability
The hardest call behind the Tag Library was structural: should it be an accordion or a drill-down? I prototyped both and tested them with users. The accordion allowed quick scanning when categories were few, but broke at production scale. With 50+ tag values per category, expanding one accordion section pushed all other categories below the fold, making cross-category scanning impossible. The drill-down structure required deeper click depth (an explicit tradeoff I accepted), but followed familiar patterns from Google Analytics and file browsers, meaning users could navigate without learning new interaction models. This was a deliberate tradeoff: I chose scalability and familiarity over shallow navigation, knowing the click-depth cost was manageable for users who already navigated hierarchical data systems daily.
OPTION A
Failed scanning when tag values exceeded 40-50 items per category; drill-down maintained scanability by keeping all categories visible
Simpler API implementation but broke at production scale
OPTION B / CHOSEN
Enterprise users valued confidence and orientation over click efficiency when managing 80,000+ files; the extra click depth was acceptable friction
Aligned with familiar patterns from Google Analytics and file system browsers, reducing learning curve
KEY DECISION 2
Designing Delete Tag without compromising data integrity or user autonomy
The hardest call in the Tag Library was Delete Tag. Tags are not isolated objects: once created, they become dependencies for Workflows, Plans, Reports, Deep Analytics queries, and the files they are applied to. Deleting a tag while any of these reference it could orphan compliance metadata, corrupt in-progress Apply operations, or silently break governance rules on files that needed the tag for retention and migration policies. Two opposite directions were on the table, and I ended up rejecting both in favor of a risk-classified hybrid that repositioned Delete Tag as a final cleanup action following Un-tag.
OPTION A
Permissive: allow Delete Tag at any time, resolve consequences asynchronously. Soft-delete first (hidden from UI, kept in storage), then hard-delete once every dependent action finished
Preserved user autonomy but pushed system cleanup into a background process that was hard to debug and harder to explain to admins managing compliance-sensitive data
OPTION B
Restrictive: block Delete Tag whenever any system referenced the tag
Predictable but devastating to use. Admins managing 80,000+ files would face tags they could never delete because some forgotten Workflow from last quarter still pointed to them, breaking the lifecycle promise of the IA
FINAL APPROACH
HYBRID / CHOSEN
High-risk dependencies (files currently carrying the tag, or an Apply Tag operation still running): block delete outright. Modal points the user to Un-tag first, protecting compliance metadata on HIPAA-regulated files
Low-risk dependencies (Workflows, Plans, Reports, or Deep Analytics queries that merely reference the tag in their saved configuration): allow delete with a warning. Soft-delete then auto hard-delete once dependent operations clear
Repositioned Delete Tag as a final cleanup that follows Un-tag, separating data-layer bindings from configuration-layer references. The same risk-classification pattern later carried into the Bulk Actions case study
IMPACT
62% faster queries, 63% fewer tickets, and policy automation adoption that exceeded projections
QUERY TIME
-62%
Average time to group target data dropped from 8 minutes to 3 minutes
SUPPORT TICKETS
-63%
Monthly filtering-related tickets declined from 8 to 3, freeing CS team capacity
POLICY AUTOMATION
+200% adoption rate
IT Admins applied tags to automated migration and backup policies faster than projected, validating the dual-use IA design
After release in Q1 2025, query creation time dropped from 8 minutes to 3 minutes, a 62% reduction. Filtering-related support tickets declined from 8 per month to 3, a 63% drop. Attribution is not perfect. We did not run an A/B test or phased rollout, a limitation of our small enterprise platform. However, no other major data browsing changes shipped in the same quarter, and filtering-related tickets declined while other categories remained flat, providing indirect but consistent evidence. This limitation directly informed the phased rollout plan in Next Steps. The unexpected win was policy automation. IT Admins began using tags as conditions for automated actions within weeks of launch, applying migration policies to data tagged Archived and backup policies to data tagged Compliance-Sensitive. This adoption exceeded projections, confirming that the dual-use information architecture had been structured correctly to support both retrieval and governance use cases from a single tagging system.
LEARNINGS
Production-scale testing reveals what prototypes hide
Before this project, I believed good design meant providing one unified experience for all users. This project taught me the opposite. When I tested an early prototype that showed the same interface to both personas, Restricted Users hesitated to use any tagging features because admin-level controls were visible. The unified approach did not feel inclusive. It felt intimidating. That was the turning point. I separated browse-and-apply for Restricted Users from create-manage-apply-delete for Admins, and both groups immediately engaged more confidently. This principle, same data model but different interaction paradigms per role, carried directly into the Bulk Actions project, where I applied the same separation to resolve a similar two-persona tension. The tactical lesson was equally important: always test IA with production-scale data. The accordion broke at 50+ tag values per category, a failure completely invisible with 5-10 sample tags in low-fidelity testing.
The unified-vs-separated decision matters more than any micro-interaction. Getting the IA structure right defined whether the system would scale; surface-level refinements could always come after launch.
Involve engineers in IA discussions during prototyping, not after design lock. Early collaboration prevented a two-week rework and built buy-in for a more complex but correct solution.
In enterprise contexts, confirmation steps for batch operations build trust, not friction. Users managing 80,000+ files need to feel confident about the scale of their actions before committing.
NEXT STEPS
From tagging to governance: naming standards, better measurement, and team-level control
Post-launch feedback revealed that tag naming inconsistencies across teams were creating governance friction as the customer base grew. I deprioritized formal naming schemas during the initial design to reduce friction and accelerate adoption, but this tradeoff created scaling risk. Phase two will introduce admin-controlled naming templates and conventions that team leads can customize without enforcing rigid rules. I also need to instrument tag adoption from day one for future releases. The causality analysis for this project relied on a clean before-and-after with no other variables, which worked for a small enterprise platform but would not scale to larger customer cohorts. A phased rollout strategy with natural comparison groups will strengthen future impact claims. Finally, I will expand role-based access control to include team-level permissions, allowing larger enterprises to delegate tag management without giving all admins full governance authority.
Design phase two naming templates and conventions for IT Admins to customize, reducing tag sprawl while preserving adoption velocity and team autonomy
Instrument tag adoption metrics from day one for future releases, including adoption rate by persona, bulk-tag creation frequency, and policy automation triggers
Plan phased rollout strategy with natural comparison groups to validate causality rather than correlation, strengthening impact measurement at scale
Expand role-based access control to include team-level tag management delegation, enabling governance at scale across large enterprises like Pfizer and Nike